Nella Gestione Elettronica dei Documenti
(GED) di solito l'accento è
posto più sulle problematiche inerenti
le tematiche dello storage, dell'information
retrieval, della security, dello sharing,
del workflow, ecc... sottovalutando,
invece, un aspetto rilevante costituito
dall'image processing.
Poiché l'elemento chiave della GED
alla fin fine è proprio il documento,
bisognerebbe prestarvi la dovuta
attenzione affinché la sua rappresentazione
come immagine digitale sia
più naturale possibile e più fedele
all'originale cartaceo, così da non far
rimpiangere il fatto di non avere tra
le mani un documento fisico, ma di
disporre soltanto di un documento
virtuale su di un monitor.
L'evoluzione tecnologica, introdotta
dalla continua ricerca nel campo
dell'elaborazione immagini ed il costante
incremento delle capacità di
elaborazione dei moderni personal
computer rendono oggi possibile operare
sulle immagini digitali in modo
estremamente efficace, impensabile
solo pochi anni fa.
Vediamo nella pratica in che modo è
possibile far sì che il computer possa
esserci di ausilio in questo compito,
analizzando da vicino le tecnologie di
image processing maggiormente utili in
ambito documentale.
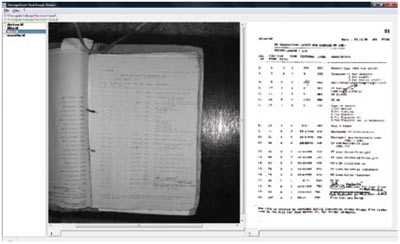
Black Border Removal e Thresholding Dinamico applicati ad una pagina di libro acquisita con scanner planetario: sulla sinistra l'immagine originale, sulla destra quella processata
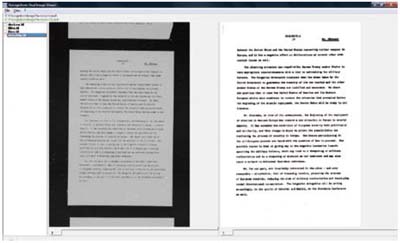
Deskew
Per l'acquisizione dei documenti, spesso
si utilizzano scanner professionali
veloci dotati di alimentatore automatico di fogli (ADF). Per le inevitabili
tolleranze della meccanica e per la
scarsa rigidità dei fogli di carta è normale
che le immagini dei documenti si
presentino leggermente inclinate verso
destra o verso sinistra invece che
perfettamente diritte e allineate con gli
assi orizzontali e verticali.
Il termine tecnico anglosassone comunemente
utilizzato per indicare
tale inclinazione è chiamato skew, che
letteralmente vuol dire pendenza, che
di solito non supera i +/- 5°.
Con il deskew è possibile raddrizzare automaticamente una immagine inclinata: sulla sinistra l'immagine originale, sulla destra quella processata.
L'operazione di correzione della
pendenza, ossia il raddrizzamento
dell'immagine, è denominata, quindi,
deskew. Tale correzione può oggi essere
eseguita in totale autonomia dal
software senza intervento umano: il
sottosistema di image processing preposto
a tale attività analizza l'immagine
per valutare l'entità dell'angolo di
inclinazione così che possa opportunamente
ruotarla per renderla perfettamente
diritta, correggendo il difetto
introdotto dalla scansione.
I tool più efficaci oggi disponibili riescono
a contenere il tempo di elaborazione
in poche frazioni di secondo ed
a raggiungere un'accuratezza davvero
elevata, arrivando anche ad 1/100 di
grado, potendo contestualmente lavorare
non soltanto su immagini monocromatiche
ma anche su immagini in
scala di grigio e a colori.
Black Border Removal
Alcune tipologie di scanner ad elevata
produttività utilizzano uno sfondo
nero, invece che bianco, per due motivi
fondamentali: evitare problemi di
trasparenza acquisendo fogli molto
sottili e consentire l'acquisizione
contemporanea di fogli di dimensioni
diverse. L'immagine del documento
acquisito può quindi presentare spessi
bordi costituiti da fasce annerite.
L'operazione di identificazione ed eliminazione
di questi bordi è chiamata
black border removal e può essere eseguita
automaticamente da una procedura
software che, dopo aver analizzato
l'immagine, può tagliare via la parte
nera aggiuntiva sui quattro lati del foglio
o può semplicemente sbiancarla,
in base alle impostazioni prescelte.
Anche in questo caso non è necessario
un intervento dell'operatore, i tempi
di elaborazione sono pressoché istantanei
e si può agire indifferentemente
su immagini in bianco e nero, in scala
di grigi e a colori.
Black Border Removal, Deskew e Thresholding Dinamico applicati ad una pagina acquisita da microfilm: sulla sinistra l'immagine originale, sulla destra quella processata.
Despeckle
Talvolta capita che le immagini acquisite
presentino dello sporco costituito
da punti neri isolati, dovuti a polvere
depositata sui sensori di acquisizione
o addirittura ad interferenze elettrostatiche
dovute a surriscaldamento dei
componenti elettronici.
Il termine anglosassone utilizzato per
identificare questa tipologia di sporco
è la parola speckle, e l'operazione di pulizia
per l'identificazione e la rimozione
di questi punti è definita despeckle.
I tool software che effettuano questo
tipo di elaborazione non necessitano
di intervento umano, sono estremamente
veloci e possono lavorare su
immagini monocromatiche, in scala di
grigio o a colori.
Quelli più efficaci possono impiegare
degli algoritmi avanzati tali che, pur
eliminando elementi di sporco molto
grandi, evitano che segni di punteggiatura
o punti sulle "i" possano essere
rimossi in modo accidentale.
Auto-orientamento
Non tutti i documenti cartacei sono
scritti in modalità "portrait", ossia,
pensando ad un foglio A4, con
l'orientamento naturale per la lettura
tale che la parte stretta sia la base del
foglio. Talvolta capita che grafici, tabelle,
schede ed elaborati simili siano
stampati in modalità "landscape",
ossia, riferendoci sempre ad un foglio
A4, con la parte larga come base del
foglio.
Quando si effettua la scansione di documenti,
la si fa sempre con il medesimo
orientamento per cui ci si troverà
con immagini correttamente ruotate
per la lettura e con altre no.
Per evitare che, durante la successiva
consultazione dei documenti,
l'operatore debba ripetutamente
usare funzioni di rotazione per poter
leggere correttamente a schermo il
documento, sono state sviluppate apposite
funzioni di auto-orientamento
che consentono di effettuare automaticamente
tale operazione in batch,
su un gruppo di documenti, senza
intervento umano. Tali tool consentono
quindi di individuare il corretto
orientamento di lettura e di decidere
autonomamente se il documento è
dritto o se ruotare automaticamente
le immagini di 90, 270 o 180 gradi.
Thresholding dinamico
Poiché la GED è essenzialmente
rivolta alla gestione di documenti
aziendali, di solito il colore non è
importante, per cui si è orientati all'acquisizione
dei documenti in modalità
monocromatica. Gli scanner, anche
quelli monocromatici, nell'acquisire
un documento effettuano di fatto
una misurazione della quantità di luce
riflessa dalla superficie del foglio, ottenendo
dai circuiti elettronici un valore
solitamente compreso tra 0 e 255.
Dovendo restituire una immagine in
scala di grigi, viene restituito proprio
tale valore, ma dovendo restituire una
immagine monocromatica, si deve
impostare un valore di soglia, al di
sotto del quale il punto è considerato
nero, al di sopra è considerato bianco.
La selezione di questa soglia è un'operazione
alquanto delicata in quanto in
base ad essa si possono ottenere documenti
leggibili oppure troppo chiari
o troppo scuri. Se una immagine è
troppo chiara, oppure troppo scura,
potrebbe risultare difficile leggere i
dati in essa contenuti, cosa alquanto
grave se non ci si accorge tempestivamente
del problema, ma solo quando
ormai è troppo tardi, quando cioè si
ha necessità del documento e l'originale
cartaceo non è più reperibile. Il
problema maggiore è però dato dal
fatto che, più spesso di quanto non
s'immagini, non c'è possibilità che
un valore di soglia, qualsiasi esso sia,
renda l'immagine leggibile in ogni sua
parte.
È per risolvere queste problematiche
che sono nati i tool di thresholding dinamico.
Praticamente invece che utilizzare
un valore di soglia valido per tutta
quanta l'immagine, viene utilizzato un
valore di soglia specifico per ciascun
punto dell'immagine, calcolato in base
a diversi algoritmi più o meno evoluti.
Con tale sistema si riesce ad evitare di
perdere scritte particolarmente chiare
su fondo chiaro o di trasformare in
macchie nere le scritte scure su fondo
particolarmente scuro.
Probabilmente questa tecnologia è
una delle più complesse e la maggior
problematicità sta nell'individuare sia
la tipologia di thresholding dinamico
più appropriata ai propri documenti,
sia gli eventuali parametri richiesti.
Comunque le ultime novità in questo
campo consentono di non dover impostare
alcun parametro così che sia
lo stesso sistema ad analizzare l'immagine
e decidere quali siano i parametri
più appropriati per processarla nel
migliore dei modi.
Color dropping
Non di rado capita che sia necessario
acquisire un documento a colori per
averne una versione fedele all'originale
per la conservazione a lungo termine,
ma nel contempo può servire una
copia monocromatica per operazioni
di lettura ottica, ossia di estrazione
dati. Si pensi ad esempio alle ricette
mediche, oppure alla modulistica
ottimizzata per la lettura ottica, che è
costituita da una parte prestampata di
un unico colore come rosso o verde,
scelto per essere rimosso direttamente
durante la fase di scansione monocromatica.
In questi casi una tecnologia che può
risultare utile è il color dropping, ossia
l'eliminazione di un range di colori
specifico dall'immagine. Viene praticamente
emulato ciò che avviene
utilizzando uno scanner dotato di
lampada colorata per il filtraggio del
colore, partendo quindi dall'immagine
a colori ed arrivando a quella monocromatica.
In questo modo, anche
acquisendo a colori, successivamente
si possono ottenere immagini monocromatiche
filtrate pronte per essere
sottoposte a lettura ottica.
Color Dropping eseguito su due tonalità (rosso e viola): sulla sinistra l'immagine originale, sulla destra quella processata.
Compressione
Anche nel campo della compressione
è possibile trarre vantaggio dai
recenti sviluppi in image processing. Ad
esempio, è possibile fare in modo che
il sistema riconosca in modo automatico
se un foglio contiene fotografie o
grafica colorata per cui sia preferibile
memorizzarlo a colori, magari con
compressione JPEG, oppure se è
adeguata una sua rappresentazione in
monocromatico ed il suo salvataggio
con compressione CCITT G4.
Non solo: è anche possibile riuscire
ad ottenere file altamente compressi
suddividendo, sempre grazie a tool
di image processing, il layer di testo
nero su fondo bianco dalle immagini
a colori, e salvando in file compound,
come ad esempio il PDF, ciascun layer
con la compressione ed il campionamento
più appropriato, senza che sia
percepibile alcuna perdita di qualità
per l'utente.
Ricampionamento
Il ricampionamento consiste nel
trasformare un'immagine da una
risoluzione ad un'altra. Ciò può essere
richiesto, ad esempio, quando si
acquisiscono dei documenti ad una
risoluzione elevata per memorizzazione
a lungo termine, ma se ne
vuole ottenere anche una versione più
"leggera" per l'utilizzo corrente, per
la distribuzione via web, etc... Utilizzando
tool appositi è quindi possibile,
ad esempio, ricampionare a 200 DPI
immagini acquisite a 300 o 400 DPI,
senza necessità di doverle riacquisire.
È addirittura possibile fare in modo
che, campionando le immagini in bassa
risoluzione per crearne miniature o
preview, vengano trasformate in scala
di grigio così da renderle maggiormente
leggibili (antialiasing).
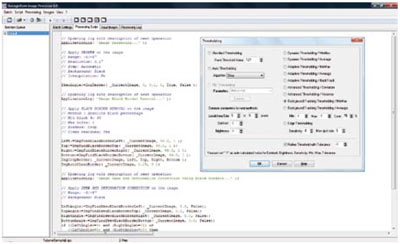
L'interfaccia utente di una diffusa applicazione di batch image processing (Recogniform Image Processor): con un sistema di wizard è possibile definire tutte le operazioni da effettuare sul lotto di immagini, senza necessità di sviluppare software specifico.
Conclusione
Queste tecnologie sono disponibili
sia come SDK (Software Development
Kit) per gli sviluppatori che desiderano
integrarle direttamente nei propri
software di gestione elettronica documenti,
sia come applicazioni pronte
all'uso, adatte all'elaborazione batch
di documenti, per gli utenti finali.
Concettualmente il software di image
processing può essere visto come una
"scatola nera" in grado di elaborare
le immagini secondo le indicazioni
impartite, senza comunque la necessità
di conoscere ed approfondire
i complessi algoritmi che sono alla
base delle sue funzionalità. Pertanto
gli sviluppatori possono considerarne
l'integrazione per migliorare le funzionalità
di software GED, così come
direttamente gli utenti finali. I centri
servizi, ad esempio, possono utilizzarle
immediatamente senza alcun
investimento in sviluppo software.
È giusto quindi dire che, considerando
l'indubbia efficacia, la facilità d'uso
ed il basso costo di queste tecnologie,
sarebbe un peccato non sfruttarle.