Let us pause a moment to look around: it is hard not to notice how, even today, in the age of digital information, paper forms continue to be widely used in many daily activities.
Students and candidates, in teaching and competition field, they are
faced with multiple choice questions that mark the right answers.
One thinks of the post bulletins which are widely used every day
to pay for utilities and services of any kind to the recipes used in pharmaceutical health care.
And yet, having to ask for a credit card, open a bank account,
adhere to collection points or subscribe to any other service it is normal that it is required to fill in a paper form.
In short, the examples that you can make are so many.
This is all due to the fact that the completion of a paper form is an operation practically to everyone that does not require particular competence or equipment to be performed and which can then be carried out at any place and time.
But the paper documents are not generated only by hand: one thinks of invoices, shipping documents, bank statements, receipts, contracts and all other documents that are printed daily to convey information from one entity to another.
While there is someone who writes the data on paper forms or documents, on the other hand, there is someone who needs to read it so that you can insert into a computer and make them processable in electronic format. This activity has been for years the bottle neck in the process of forms processing and document storage.
But what could be done years ago using only data entry, or manually entering data into the computer keyboard, today can be done using document scanners and sophisticated software procedures commonly called data capture.
For data capture means essentially the automatic conversion of printed information on paper into digital information manipulable , just as if they were transcribed by an operator at a keyboard of computer.
Because this conversion must be done on computer systems, it is clear that
behind all require a process of digitization, namely digital conversion than this on paper.
Scanning support paper using a documents scanner produces images faithful to the source documents,
but which have no intelligible information content from a computer.
In fact, the digitization produces something similar to photographs, images, grids of pixels,
bitmaps that are to be compiled and interpreted to do in order to extract the information contained
therein and to treat them in electronic format.
The complication comes from the fact that paper based information may be present
as typewritten or printed text as handwritten in capital letters or in italics,
such as check marks or barcodes: it is clear therefore that transform everything from dots
(pixels) data (ASCII/unicode), although it is a natural ability and unconscious by a human operator,
it's extremely difficult for a computer program.
To treat each type of information is used for advanced recognition technologies,
created and evolved in a relatively recent period,
which is usually done with reference acronyms such as OMR, OCR, ICR, etc.
Sometime between the layman is generated confusion between optical storage
and data capture, but it should be noted that these are two separate things,
although often complementary.
Imagining, for example, to acquire with a documental scanner and digitize the documents and statements
that we send our bank every month, we get a series of images that can be stored as a file on your computer,
perhaps in an optical storage system, giving it a better name or less significant,
then display them and read them on screen exactly as if we had the paper in front.
But, just like the paper, if we were
to verify the presence of a transfer of a certain amount,
we should "flip" these documents one by one because we could not use any functionality to automatically search for:
to do that we should first submit to data capture this documents,
so as to extract the information contained therein and make them intelligible
from the computer so as to use them for our purposes.
This is why the data capture can be aimed not only at the data capture,
but also to document capture, to be complementary optical archiving and
allow you to automatically extract all the data from the
scanned documents to be used as classification keys,
as well as allow to search for content (full text) on the same documents.
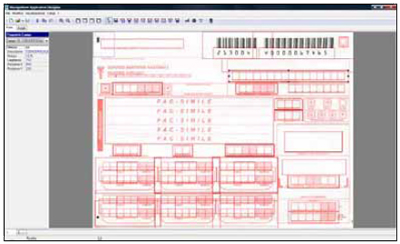
A structured documents is a module with layout and disposition of information are fixed between specimens of the same type or class.
For example the pharmaceutical recipe is a good example of structured document:
the space to accomodate the fiscal code, the data, the ticks and all other information of patient
is always the same and does not vary from recipe to recipe.
For these types of documents have been used
advanced technologies for optical character recognition (OMR, OCR, ICR, BCR, CHR)
and sophisticated image processing algorithms to realize that automate the entire process of data acquisition.
On the practical side, using user interfaces more or less user-friendly, for
each type of paper document structure to process,
it is sufficient to prepare a specific template, which define the coordinates and size of the areas to be read.
Once scanned and converted into an image, the modules are processed in an automatic and unattended
to then be released in a database or a file.
If some data is unreadable or questionable reading, before they go into outputs,
can be required the intervention of an operator, in assisted mode, can verify and correct, if necessary.
This type of operation is made possible by the fact that, having to do
with structured documents, all the modules of a certain class are identical
to each other for which it is known a priori in that position find a certain given and which are the possible
steps make propedeuticamente (removal boxes, color filtering, intrusion deletions, etc..) to be able to read it correctly, minimizing the possibility of error.
Obviously the modest changes in position (shift), rotation (skew) and size
(stretch) due to the inevitable friction of the sheets during the scanning process can be compensated automatically by the software.
This is especially true if the paper form has been specifically designed and optimized for the data capture,
using all those tricks that can improve and simplify the task.
These technologies for data capture of structured forms are now available for several years
and have reached a very high degree of maturity, laying the groundwork for new challenges:
the data capture of documents to free structure is one of them.
If a structured document is any type of module in which the positions of
the data to be extracted are precise and well-known in advance,
an unstructured document is instead a document in which there are, however, very precise data,
but their position and the their layout is not known a priori
and can vary greatly between the document and the document of the same typology.
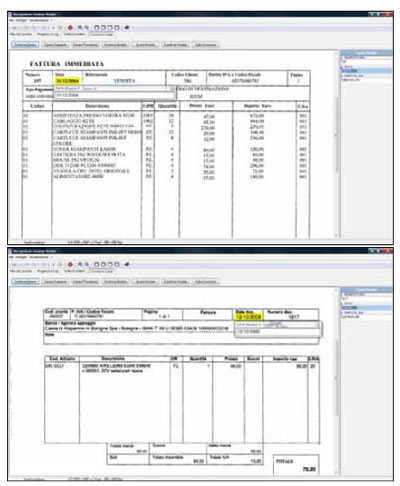
The most classic example of unstructured document in which it is very easy
to come across on a daily basis is represented by bills: although
we know a priori that each invoice is the name of the supplier, the date, the serial number, the assessment, the VAT and the total,
we can not know in advance where these data are located.
In fact, their position is not standardized, it is left to the free will of each supplier
that you can indulge to use fonts, graphics, colors and shadows as they see fit.
One of the possible strategies to deal with these types of documents is to
be traced back to the case of homogeneous structured documents, where feasible.
For example, continuing to talk about the bills, you might create a specific template
to associate with the invoices of each vendor, so that once identified the supplier,
the invoice can be treated in an appropriate way.
This approach can be good when the number of classes is not high,
and when the process of classification can be done accurately, whether
performed directly by software or manually by an operator.
We must therefore prepare to worry about the different template to quote
and be certain that they are processed only documents related to them.
In contrast to other types of unstructured documents, such as currucula,
this type of strategy is not applicable.
The approach that is used to solve this problem, rather than starting from a spatial definition,
part by a logical definition of the data.
In practice, the read data are defined, and then identified by a series of specific attributes,
such as, for example, key words next to them, formatting type waiting,
relative position, presence or absence of graphical elements, criteria of cross validation to be checked, and so on.
In the case of VAT as an invoice, for example, will be able to recognize it,
and then obtain the value, instructing the system to find a sequence of 11 numeric characters
(or 2 letters followed by 11 digits), close (above, below, right , left) of the words " VAT " or " VAT " or " VAT ", etc.,
perhaps limited to a certain area of the document (for example in the top half of the image),
verifying the checksum and, if possible, in the presence of a possible database of suppliers.
In practice, the software instructs you to "think" like humans do:
in fact, when we look on a bill given the TOTAL DOCUMENT we are naturally inclined to look at the bottom right of the sheet,
maybe we focus on a particularly clear or marked box and try as "proof" the words "TOTAL DOCUMENT" O "INVOICE AMOUNT" or
"TOT. INVOICE".
In the same way it acts a system for processing unstructured documents:
this is based on our information, that is, on the basis of the rules properly reset,
which must then be defined in a precise and exhaustive.
Underlying these features is the use of optical character recognition (OCR)
of the entire document together with a robust algorithm for layout analysis:
the combined use of these two tools makes it possible to identify blocks of text, vertical lines, horizontal
and text elements with their confidences, hence the possibility of verifying whether or not the logical conditions
imposed on the research data on the page.
To make it even more accurate processing of unstructured documents
is also possible to combine the two strategies described above:
if the system is able to associate the document to be treated to a template known,
is treated as a structured document, otherwise it is treated as a document unstructured and processed equally.