Soffermiamoci un momento a guardarci intorno: è difficile non notare
come, ancora oggi, nell'era dell'informazione digitale, i moduli cartacei
continuano ad essere largamente utilizzati in molteplici attività quotidiane.
Studenti e candidati, in ambito didattico e concorsuale, si trovano davanti
a questionari a scelta multipla in cui marcare le risposte giuste. Si pensi
anche ai bollettini postali che sono largamente utilizzati ogni giorno per
pagare utenze e servizi di ogni tipo o alle ricette farmaceutiche utilizzate in
ambito sanitario. Ed ancora, dovendo richiedere una carta di credito, aprire
un conto in banca, aderire ad una raccolta punti o sottoscrivere un
qualsiasi altro servizio è normale che sia richiesto di compilare un apposito
modulo cartaceo. Insomma gli esempi che si possono fare sono davvero
tanti.
Tutto ciò è dovuto al fatto che la compilazione di un modulo cartaceo è
un'operazione praticamente alla portata di tutti che non richiede
attrezzature o competenze particolari per essere eseguita e che può quindi
essere svolta in qualunque luogo e momento.
Ma i documenti cartacei non sono generati solo a mano: si pensi a fatture,
documenti di trasporto, estratti conto, ricevute, contratti e tutti gli altri
documenti che sono stampati quotidianamente per veicolare informazioni
da un soggetto all'altro.
Se da un lato c'è qualcuno che scrive dei dati su documenti o moduli
cartacei, dall'altro lato c'è qualcuno che ha necessità di leggerli così da
poterli inserire in un computer e renderli elaborabili in formato elettronico.
Tale attività ha rappresentato per anni il collo di bottiglia nei processi di
elaborazione dei moduli e di archiviazione dei documenti.
Ma ciò che anni addietro si poteva fare ricorrendo esclusivamente al data
entry, ossia all'immissione manuale di dati nel computer da tastiera, oggi
può essere fatto utilizzando scanner documentali e sofisticate procedure
software comunemente chiamate di lettura ottica.
Per lettura ottica s'intende essenzialmente la conversione automatica di
informazioni stampate su supporto cartaceo in informazioni digitali
manipolabili, esattamente come se fossero state trascritte da un operatore
alla tastiera di un computer.
Poiché tale conversione deve avvenire su sistemi informatici, è chiaro che a
monte di tutto è richiesto un processo di digitalizzazione, ossia di
conversione in digitale di quanto presente su supporto cartaceo.
La scansione dei supporti cartacei mediante scanner documentali produce
delle immagini fedeli ai documenti di origine, ma che sono prive di
contenuto informativo intellegibile da un computer. Infatti, la
digitalizzazione produce qualcosa di simile a fotografie, immagini, griglie di
pixel, mappe di bit che vanno elaborate ed interpretate per fare in modo di
estrarre i dati ivi contenuti e poterli trattare in formato elettronico.
La complicazione è data dal fatto che su supporto cartaceo le informazioni
possono essere presenti come testo dattiloscritto o stampato, come testo
scritto a mano in stampatello o in corsivo, come segni di spunta o come
codici a barre: è evidente quindi che trasformare tutto ciò da puntini (pixel)
a dati (caratteri ASCII/unicode), sebbene sia una capacità naturale ed
inconscia per un operatore umano, è una cosa estremamente ardua per un
programma informatico.
Per trattare ciascuna tipologia di informazione si ricorre ad avanzate
tecnologie di riconoscimento, nate ed evolutesi in un periodo
relativamente recente, cui si fa solitamente riferimento con degli acronimi
quali OMR, OCR, ICR, etc.
Talvolta tra i non addetti ai lavori si genera confusione tra archiviazione
ottica e lettura ottica, ma è bene sottolineare che si tratta di due cose
distinte, sebbene spesso complementari. Immaginando, ad esempio, di
acquisire con uno scanner documentale e digitalizzare gli estratti conto che
ci invia la nostra banca ogni mese, otteniamo una serie di immagini che
possiamo memorizzare sul computer come file, magari in un sistema di
archiviazione ottica, attribuendogli un nome più o meno significativo, per
poi visualizzarle e leggerle a video esattamente come se avessimo il
cartaceo davanti. Ma, esattamente come per il cartaceo, se dovessimo
verificare la presenza di un bonifico di un certo importo, dovremmo
"sfogliare" questi documenti ad uno ad uno giacché non potremmo
utilizzare alcuna funzionalità di ricerca automatica: per farlo dovremmo
prima sottoporre a lettura ottica tali documenti, così da estrarne i dati ivi
contenuti e renderli intellegibili dal computer sì da usarli per i nostri scopi.
Ecco quindi che la lettura ottica può essere finalizzata non soltanto al data
capture, ma anche al document capture, per essere complementare
all'archiviazione ottica e consentire di estrarre automaticamente dai
documenti digitalizzati tutti i dati da usare come chiavi di classificazione,
oltre che consentire di eseguire ricerche per contenuto (full text) sui
documenti stessi.
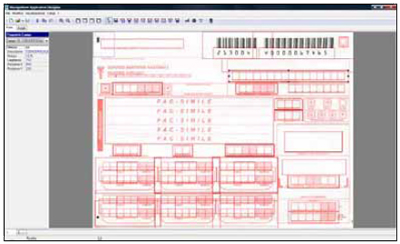
Un documento strutturato è di fatto un modulo in cui il layout e la
disposizione delle informazioni non varia tra gli esemplari della medesima
tipologia o classe.
Ad esempio la ricetta farmaceutica è un buon esempio di documento
strutturato: lo spazio per accogliere il codice fiscale dell'assistito, la data, le
fustelle e tutte le altre informazioni è sempre lo stesso e non varia da
ricetta a ricetta.
Per queste tipologie di documenti sono state utilizzate avanzate tecnologie
di riconoscimento ottico (OMR, OCR,
ICR, BCR, CHR) e sofisticate funzioni di
image processing per realizzare algoritmi che consentono di automatizzare
l'intero processo di acquisizione dei dati.
Dal lato pratico, utilizzando interfacce utente più o meno user-friendly, per
ciascuna tipologia di documento cartaceo strutturato da elaborare, è
sufficiente predisporre un apposito template, ossia definire coordinate e
dimensioni delle aree da leggere. Una volta scanditi e convertiti in
immagine, i moduli sono elaborati in modo automatico e non presidiato
per poter poi essere rilasciati in un database o su file. Nel caso alcuni dati
siano illeggibili o di lettura dubbia, prima che vadano in output, può essere
richiesto l'intervento di un operatore che, in modalità assistita, possa
verificarli ed eventualmente correggerli.
Questo tipo di operatività è resa possibile dal fatto che, avendo a che fare
con documenti strutturati, tutti i moduli di una certa classe sono identici
tra loro per cui è noto a priori in che posizione trovare un certo dato e
quali sono gli eventuali passi da compiere propedeuticamente (rimozione
caselle, filtraggio colore, eliminazioni intrusioni, etc.) per riuscire a leggerlo
nel modo corretto minimizzando la possibilità di errore.
Ovviamente le modeste variazioni di posizione (shift), di rotazione (skew) e
di dimensione (stretch) dovuti agli inevitabili attriti dei fogli durante il
processo di scansione possono essere compensati in modo automatico dal
software. Ciò è particolarmente vero se il modulo cartaceo è stato
appositamente disegnato ed ottimizzato per la lettura ottica, utilizzando
tutti quegli accorgimenti che possono migliorare e semplificare tale
attività.
Queste tecnologie per la lettura ottica di moduli strutturati sono ormai
disponibili da diversi anni ed hanno raggiunto un grado di maturità molto
elevato, gettando le basi per nuove sfide: la lettura ottica di documenti a
struttura libera è una di queste.
Se un documento strutturato è un qualunque tipo di modulo in cui le
posizioni dei dati da estrarre sono ben precise e conosciute in anticipo, un
documento non strutturato è invece un documento in cui ci sono
comunque dei dati ben precisi, ma la loro posizione ed il loro layout non è
noto a priori e può variare notevolmente tra documento e documento
della stessa tipologia.
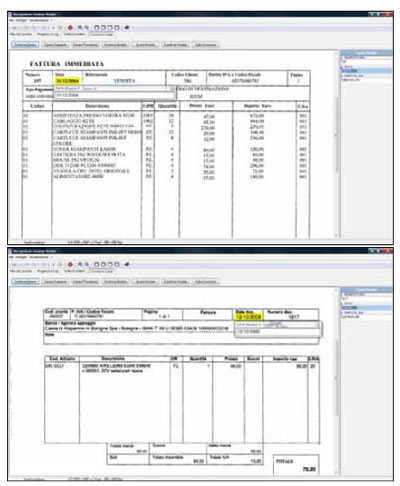
Il più classico esempio di documento non strutturato in cui è molto facile
imbattersi quotidianamente è rappresentato dalle fatture: sebbene
sappiamo a priori che in ciascuna fattura c'è la ragione sociale del
fornitore, la data, il numero progressivo, l'imponibile, l'iva ed il totale, non
possiamo sapere in anticipo dove questi dati si trovino. Infatti il loro
posizionamento non è standardizzato ma è lasciato al libero arbitrio di
ciascuno fornitore che si può sbizzarrire ad usare font, elementi grafici,
ombreggiature e colori come meglio crede.
Una delle strategie possibili per trattare questi tipi di documenti è di
ricondurli al caso dei documenti strutturati omogenei, qualora fattibile. Ad
esempio, continuando a parlare delle fatture, si potrebbe creare un
template specifico da associare alle fatture di ciascun fornitore, così che
una volta individuato il fornitore, la fattura possa essere trattata in modo
idoneo.
Questo approccio può andar bene quando il numero di classi non è elevato
e quando il processo di classificazione può avvenire in modo accurato, sia
esso eseguito direttamente dal software o manualmente da un operatore.
Bisogna infatti preoccuparsi di predisporre i diversi template in modo
preventivo ed essere certi che siano processati soltanto i documenti
riconducibili ad essi.
Di contro per altri tipi di documenti non strutturati, come ad esempio i
currucula, questo tipo di strategia non è applicabile.
L'approccio che è utilizzato per risolvere questa problematica, piuttosto
che partire da una definizione spaziale, parte da una definizione logica del
dato. In pratica i dati da leggere sono definiti, e quindi identificati,
mediante una serie di attributi specifici, quali, ad esempio, parole chiave
ad essi prossime, tipo di formattazione attesa, posizione relativa, presenza
o assenza di elementi grafici, criteri di cross validation da verificare, e così
via.
Nel caso del dato partita iva di una fattura, ad esempio, sarà possibile
riconoscerlo, e quindi ricavarne il valore, istruendo il sistema a trovare una
sequenza di 11 caratteri numerici (o 2 lettere seguite da 11 caratteri
numerici), in prossimità (sopra, sotto, a destra, a sinistra) delle parole
"P.IVA" o "Partita Iva" o "PARTITA IVA", etc., magari limitatamente ad una
certa zona del documento (ad esempio nella metà superiore
dell'immagine), verificandone il checksum e, se possibile, la presenza in un
eventuale database di fornitori.
In pratica si istruisce il software a "ragionare" come facciamo noi umani:
infatti quando dobbiamo cercare su una fattura il dato TOTALE
DOCUMENTO siamo naturalmente portati a guardare in basso a destra del
foglio, magari ci soffermiamo su un riquadro particolarmente evidente o
marcato e cerchiamo come "prova" le parole "TOTALE DOCUMENTO" O
"IMPORTO FATTURA" o "TOT. FATTURA". Nello stesso modo agisce un
sistema di elaborazione di documenti non strutturati: ciò avviene sulla
base delle nostre indicazioni, sulla scorta cioè delle regole
opportunamente reimpostate, che devono quindi essere definite in modo
preciso ed esaustivo.
Alla base di queste funzionalità c'è l'utilizzo del riconoscimento ottico
(OCR) di tutto il documento in sinergia con un robusto algoritmo di analisi
del layout: l'utilizzo combinato di questi due strumenti rende possibile
l'identificazione dei blocchi di testo, delle linee verticali, orizzontali e degli
elementi di testo con le rispettive confidenze, da cui deriva la possibilità di
verificare o meno le condizioni logiche imposte per la ricerca dei dati sulla
pagina.
Per rendere ancora più accurata l'elaborazione di documenti non
strutturati è anche possibile combinare le due strategie sopra descritte: se
il sistema è in grado di associare il documento da trattare ad un template
noto, è trattato come documento strutturato, altrimenti è trattato come
documento non strutturato e processato ugualmente.