Come classificare automaticamente documenti, fax e email
Un importante vantaggio, spesso sottovalutato,
offerto dalla lettura ottica è la possibilità di poter
effettuare l'elaborazione simultanea di
documenti di tipologia diversa, lasciando al
software l'incombenza di riconoscerne la natura
per poterli trattare ciascuno secondo le proprie
specifiche.
Si tratta di un vero e proprio processo di
classificazione automatica, ossia di attribuzione di
un documento ad una classe documentale (es:
fattura, ordine, contratto, reclamo, sollecito,
etc...) che può essere applicato sia a moduli
strutturati sia a documenti non strutturati.
Laddove possibile, può essere utilizzata una
tecnica di form identification, ossia di
identificazione del modulo, che avendo una
struttura fissa ed invariabile, può essere appunto
riconosciuto verificando la presenza di elementi
grafici costanti quali linee, marchi, caselle e
fincatura in genere. Solitamente l'utilizzo di tale
tecnica richiede una fase di "addestramento" in
cui al sistema si sottopongono i campioni di
moduli da riconoscere così che possa estrarne le
features grafiche e crearsi una sorta di database
da utilizzare per la successiva identificazione delle
istanze sconosciute.
Quando non si tratta di moduli viene invece
utilizzata una tecnica di keywording, ossia di
identificazione di parole chiave significative,
previo OCR dell'intera pagina, che costituiscono
una sorta di minimo comun denominatore per
ogni tipologia di documento da processare.
L'identificazione di tali keyword può avvenire in
modo manuale oppure in modo automatico. Nel
primo caso è lasciato alla sensibilità ed
esperienza di un operatore l'identificare quali
siano le keyword da usarsi per ciascuna classe
documentale. Nel secondo caso tali keyword
vengono invece identificate automaticamente dal
sistema sottoponendogli un sufficiente numero di
documenti per ciascuna delle tipologia tra cui
distinguere.
E' importante sottolineare che tale tecnologia
può essere usata anche quando si elabora una
sola tipologia di documento, ma multi-pagine, per
verificare l'esatto ordinamento delle facciate che
lo compongono così da essere certi che non ci
siano stati errori di scansione che potrebbero
portare alle immaginabili conseguenze in caso di
salto o di scambio pagina.
Da non sottovalutare è anche uno dei
"sottoprodotti" che possono risultare in modo
naturale dalla classificazione dei documenti, ossia
la possibilità di ottenerne il corretto
orientamento, correggendo eventuali scansioni
sotto-sopra.
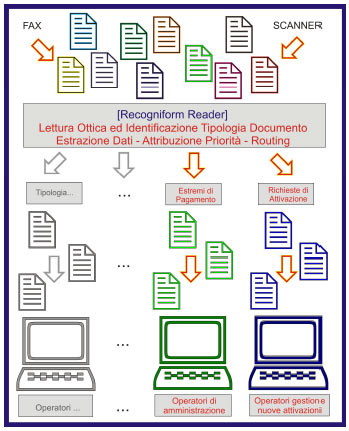
Per meglio chiarire gli ambiti di applicazione di
tale tecnologia, riportiamo quale esempio
un'applicazione reale realizzata per il servizio di
customer care di un importante operatore
telefonico italiano. L'esigenza di partenza era
quella di poter fare in modo che a ciascun
documento ricevuto potesse essere attribuita la
giusta destinazione per la sua "lavorazione" ed
una priorità in base alla specifica tipologia.
Infatti, confluendo le richieste dei clienti in un
unico flusso digitale, sia mediante fax server che
mediante scansione massiva del cartaceo
ricevuto in casella postale, non era possibile
attribuirvi priorità e routing a priori a meno che
degli operatori umani non valutassero
manualmente il contenuto di ciascuno di essi.
Utilizzando la nostra piattaforma di lettura ottica,
Recogniform Reader, è stato invece possibile fare
in modo che tali documenti venissero classificati
automaticamente, sia mediante form identification
che keywording, così da attribuire
immediatamente priorità e routing a ciascuno di
essi.
Esempio di architettura per l'identificazione e lo smistamento automatico dei documenti implementata con Recogniform Reader presso il customer care di un importante operatore telefonico.
Lo scenario iniziale era dunque quello in cui, a
fronte di una coda di migliaia di documenti da
lavorare giornalmente, l'attività si poteva
svolgere solo sequenzialmente, con operatori che
manualmente guardavano a video i singoli
documenti per decidere a chi inoltrarli e se
lavorarli subito o meno, in base alle direttive
ricevute. Lo scenario finale è diventato invece
quello in cui ciascun operatore di customer care
riceve i documenti che deve lavorare già in ordine
di priorità ed addirittura già con parte dei dati
"estratti" pronti per essere inseriti nel
CRM/Gestionale aziendale!
Un vantaggio enorme quindi che si concretizza in
un risparmio di tempo e risorse ed in un
miglioramento della qualità del servizio offerto
all'utente.